Nghiên cứu giới thiệu một phương pháp mới để tinh chỉnh mô hình ngôn ngữ lớn (LLMs), tập trung vào lý giải cảm xúc đảo chiều nhằm hiểu sâu hơn về sự thay đổi cảm xúc trong hội thoại.
Người thực hiện
Vỹ Nguyễn và GS. Xiaohui Zhang, Đại học RMIT
Chương trình
Thạc sĩ Trí tuệ nhân tạo
Thành tựu nổi bật
Đạt giải Nhì tại SemEval 2024 – cuộc thi quốc tế với sự tham gia của 84 đội từ khắp nơi trên thế giới
Khai thác chiều sâu cảm xúc trong hội thoại với mô hình ngôn ngữ lớn
Cảm xúc là yếu tố quan trọng trong giao tiếp con người, không chỉ phản ánh trạng thái tâm lý mà còn ảnh hưởng đến cách chúng ta cảm nhận, lý giải và đưa ra quyết định. Dự án này khai thác khả năng của các mô hình ngôn ngữ lớn (LLMs) trong việc nhận diện và lý giải sự chuyển biến cảm xúc trong hội thoại — đặc biệt là hiện tượng “đảo chiều cảm xúc” (Emotion Flip Reasoning).
Khác với các mô hình truyền thống chỉ đơn thuần nhận diện cảm xúc, phương pháp tiếp cận mới này sử dụng chiến lược tinh chỉnh theo chuỗi hướng dẫn (stacked-instruction) để giúp mô hình không chỉ xác định cảm xúc mà còn phân tích nguyên nhân và hậu quả của sự thay đổi cảm xúc trong quá trình đối thoại.
Mô hình nghiên cứu và phương pháp thực hiện
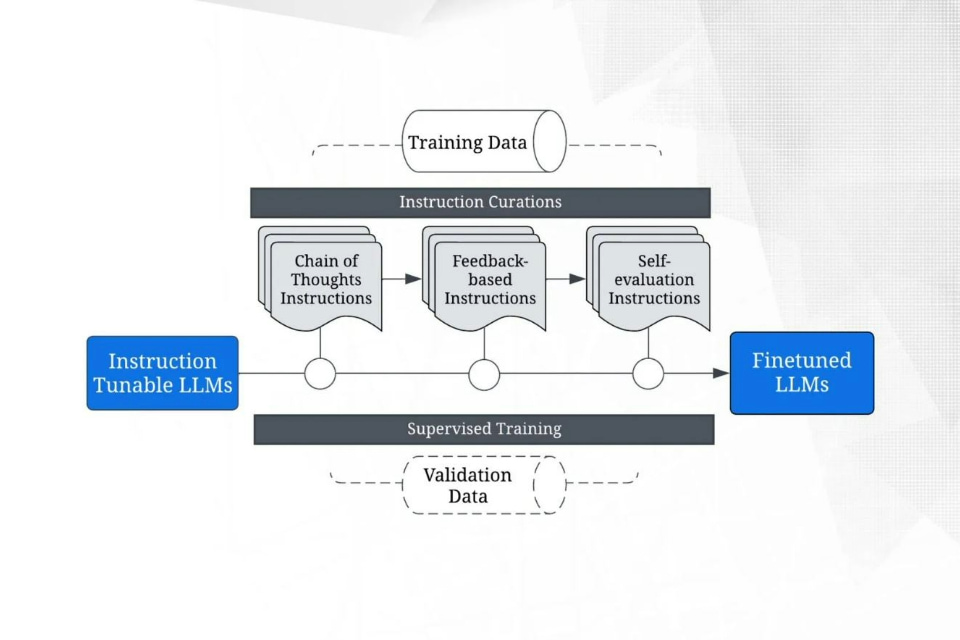 Lưu đồ thể hiện quy trình huấn luyện cho các mô hình ngôn ngữ lớn (LLMs) có khả năng tinh chỉnh theo chuỗi hướng dẫn, sử dụng các hướng dẫn được tuyển chọn để đạt được tinh chỉnh.
Lưu đồ thể hiện quy trình huấn luyện cho các mô hình ngôn ngữ lớn (LLMs) có khả năng tinh chỉnh theo chuỗi hướng dẫn, sử dụng các hướng dẫn được tuyển chọn để đạt được tinh chỉnh.
Mô hình gồm ba giai đoạn chính:
- Huấn luyện mô hình với các chuỗi suy nghĩ (Chain-of-thoughts)
- Tinh chỉnh theo hướng dẫn cụ thể về cảm xúc (Emotion instruction tuning)
- Kết hợp chiến lược đồng nhất hóa (Self-consistency) để nâng cao độ chính xác
Luồng huấn luyện được xây dựng từ các bộ dữ liệu hội thoại tiếng Anh - Hindi và tiếng Anh - Anh có cảm xúc đảo chiều, sử dụng GPT làm mô hình nền tảng.
Thiết lập thí nghiệm
- Bộ dữ liệu: MatSci (5000+ hội thoại hỗn hợp Hindi–Anh), MELD (5000+ hội thoại tiếng Anh)
- Tiêu chí đánh giá: Điểm F1 dựa trên độ chính xác của các câu thoại chứa cảm xúc đảo chiều
- Mô hình nền: GPT và các mô hình mã nguồn mở
Đánh giá kết quả và kết luận chính từ nghiên cứu
Nghiên cứu đề xuất một chiến lược tinh chỉnh mô hình ngôn ngữ lớn (LLMs) theo chuỗi hướng dẫn (stacked-instruction fine-tuning) nhằm giải quyết bài toán Lý giải cảm xúc đảo chiều (Emotion Flip Reasoning – EFR) trong hội thoại.
Các kết quả thực nghiệm cho thấy phương pháp này mang lại hiệu quả vượt trội so với các cách tiếp cận hiện có.
Kết luận chính của nghiên cứu gồm
- Tính hiệu quả của mô hình: Mô hình đạt điểm F1 lần lượt là 0.77 trên tập dữ liệu Hindi–Anh và 0.76 trên tập dữ liệu tiếng Anh, cao hơn các mô hình baseline hiện tại trong cùng tác vụ. Điều này khẳng định tính khả thi của phương pháp tinh chỉnh đa tầng đối với bài toán nhận diện cảm xúc phức tạp.
- Khả năng suy luận cảm xúc: Không chỉ dừng lại ở việc phân loại cảm xúc, mô hình có thể suy luận về nguyên nhân, động cơ và hệ quả của sự thay đổi cảm xúc trong từng ngữ cảnh hội thoại. Đây là bước tiến đáng kể so với các mô hình chỉ gán nhãn cảm xúc ở mức bề mặt.
- Tăng cường khả năng diễn giải ngữ nghĩa: Phân tích định tính cho thấy mô hình có thể tạo ra các chuỗi suy luận mang tính ngữ cảnh, phản ánh chiều sâu trong việc hiểu cấu trúc hội thoại, sự thay đổi vai trò người nói và chuyển dịch cảm xúc theo tiến trình tương tác.
- Tác động so sánh với phương pháp truyền thống: Kết quả cho thấy việc tinh chỉnh theo hướng dẫn với cấu trúc logic rõ ràng và có mục tiêu giúp mô hình học được các biểu hiện cảm xúc ngầm ẩn, vượt trội hơn so với phương pháp huấn luyện học sâu chỉ dựa vào dữ liệu gán nhãn.
- Tính ổn định của mô hình: Việc áp dụng chiến lược đồng nhất hóa đầu ra (self-consistency decoding) giúp mô hình tạo ra các dự đoán nhất quán và ổn định hơn trong các tình huống hội thoại có tính biến động cao.