The research presents a novel approach for fine-tuning large language models (LLMs), with a focus on Emotion Flip Reasoning to understand emotion dynamics in conversations.
Contributors
Vy Nguyen and Professor Xiuzhen Zhang, RMIT University
Program
Master of Artificial Intelligence
Notable achievement
The research achieved second ranking at Semantic Evaluation 2024 amongst 84 teams worldwide
Unlocking emotional dynamics in conversations with LLMs
Emotions are an integral part of human communication. Emotions extend beyond the confines of internal psychological states, functioning as a mechanism for expressing our subjective experiences and stimulating corresponding responses from others, thereby significantly shaping the dynamics of communicative interactions. Understanding the triggers for an individual's emotional dynamics during their communication with others provides explainability into the underlying drivers of their behaviours and decision-making.
Large language models (LLMs) are increasingly capable of understanding complex aspects of human language, including emotions. The research presents a novel approach for fine-tuning LLMs to better understand the dynamics of emotion in conversations. Specifically, the researchers focus on the challenge of Emotion Flip Reasoning (EFR), which involves identifying the utterances that cause a speaker to shift from one emotion to another. Their framework uses a stacked instruction-based approach, where LLMs are fine-tuned on a series of increasingly complex instructions related to emotions and conversational flows. This allows the model to learn subtle cues and patterns in language that indicate emotional shifts. This research highlights the potential of LLMs to not only recognise emotions in text but also to reason about the causes and consequences of emotional change in conversational exchanges.
Research model and methodology
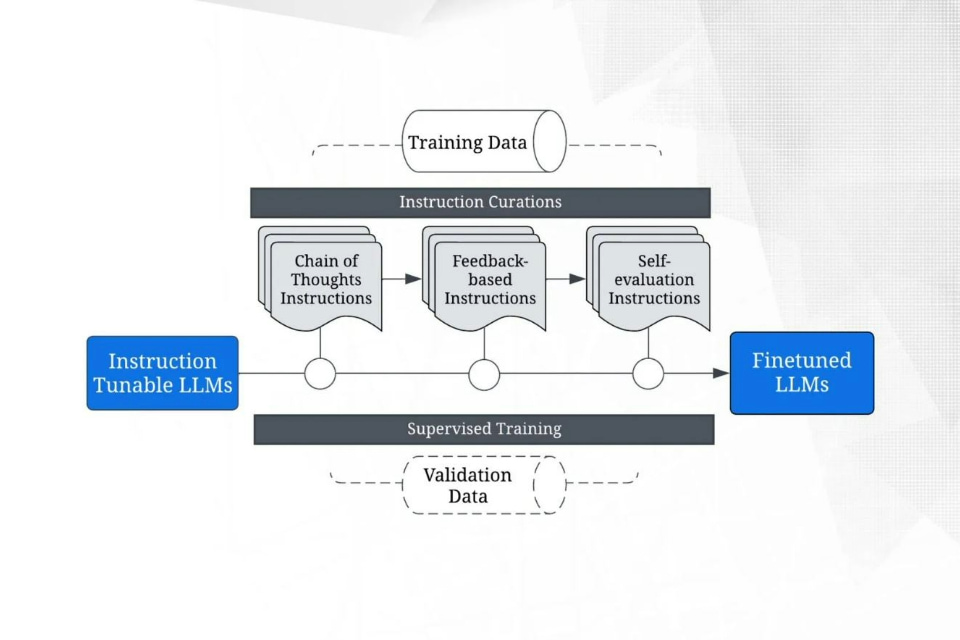 Flowchart depicting the training pipeline for instruction-tunable LLMs, using curated instructions to achieve fine-tuning.
Flowchart depicting the training pipeline for instruction-tunable LLMs, using curated instructions to achieve fine-tuning.
The system must be built upon an instruction-tunable LLM. The instruction tuning strategy involves a stacked pipeline of three stages:
- Train base models with chain-of-thoughts (CoT) instructions, teaching the model what is correct
- Provide feedback-based instructions to the tuned model, expecting it to rectify its discrepancies
- Provide self-evaluation instructions to the tuned model, expecting it to improve itself through autonomous evaluation.
The research utilises self-consistency (SC) inference strategy on the final tuned model to increase prediction consistency.
Experiment setup
- Datasets: MaSaC (5000+ Hindi-English code-mixed dialogues from Sarabhai vs Sarabhai) and MELD (5000+ English dialogues American TV sitcom Friends)
- Evaluation metric: F1 score of the identified trigger utterances
- Base models: GPT families and open-sourced models.
Key findings and evaluation
The final research models yielded plateau F1 scores of 0.77 for the Hindi-English track and 0.76 for the English-only track. Experiments showed that flips between neutral and joy were the most prevalent. Furthermore, ablation analysis demonstrated a consistent improvement in performance with the addition of each instruction set. Moreover, the CoT instructions in step one emerged as the most impactful, reducing error rates by 38%. Tuned models were shown to possess cross-lingual generalisability. Hallucinations involving anomalous trigger predictions were observed.
These results highlight the significant impacts and insights gained from this research. Emotion Flip Reasoning (EFR) provides insights into the underlying drivers of emotion shifts in conversational exchanges. Instruction tuning benefits significantly from the provision of high-quality instructions, as evidenced by the progressively improved performance of the pipeline. Large Language Models (LLMs) demonstrate superior reasoning about emotion shifts compared to traditional machine learning and deep learning approaches.
Future directions
Future research will explore multi-task learning models to recognise emotions and reason about their shifts within a single, unified process. Additionally, investigations into multimodalitites, including audio and video, aim to provide a more holistic understanding of emotional dynamics by considering non-verbal cues and information often omitted during transcription.